Los métodos de análisis de la estadística tradicional y los métodos de minería de datos y aprendizaje computerizado comparten una característica básica y esencial: la presencia de variabilidad que se pretende reducir si bien con objetivos diferentes aunque no necesariamente antagónicos.
En efecto, las técnicas de Minería de Datos y Aprendizaje Computerizado priman la finalidad de clasificar o predecir el resultado de un determinado fenómeno, evento o comportamiento (por ejemplo abandonar un proceso de compra ”online” o dejar de ser clientes de una determinada compañía) versus la finalidad de explicar por qué se produce. Delegan la búsqueda de ese porqué en algoritmos y métodos bien definidos que son entrenados sobre un conjunto de datos mediante la optimización de alguna función objetivo – usualmente relacionada con los costes de predicción errónea- que es afinada de forma heurística para permitir la generalización del sistema de predicción a conjuntos de datos similares pero diferentes de aquel sobre el que han aprendido. Lo que importa es predecir o clasificar correctamente las observaciones y generalizar el sistema. Un método de predicción es bueno cuando reduce la variabilidad de respuesta entre los grupos que clasifica: la variabilidad del fenómeno “abandono” o “churn” es menor dentro de los grupos según el resultado de la clasificación obtenida que cuando se considera la población globalmente. No es de extrañar que las técnicas de este tipo sean exitosas en el mundo empresarial -sin descartar otros ámbitos igualmente beneficiosos- donde se intenta cuantificar la incertidumbre para transformarla en riesgos calculados sin que sea indispensable detallar la explicación de sus causas.
Al sacrificar relativamente la explicación de las causas de un evento en favor del resultado de predicción, paralelamente a la mejora exponencial y abaratamiento de las capacidades de cómputo reciente, este conjunto de técnicas ha evolucionado para ser capaces de acomodar cada vez más variables que aportan mejoras marginales a los modelos que superan sus costes marginales. Enseguida vislumbraremos también otra ventaja no menor: si el objetivo es predecir o clasificar, alcanzarlo a través del análisis estadístico tradicional -en aquellos casos donde puede haber aproximaciones concurrentes ante un mismo desafío predictivo- requiere enfrentarse a una casuística de modelización compleja como se explica a continuación.
La aproximación “estadística” se centra en el análisis de las diferencias comparativas de variabilidad con el fin de identificar, cuantificar y explicar los efectos sistemáticos que algunos factores tienen sobre un determinado fenómeno. La explicación de tal variabilidad requiere su descomposición en componentes que tendrán necesariamente una variabilidad reducida. Por ejemplo, el efecto que la frecuencia semanal de una determinada técnica de fisioterapia tiene sobre el tiempo de recuperación de los pacientes de una lesión concreta, tratando de aislar ese efecto de los atribuibles a otras causas como la edad de los individuos, su condición física, su estado de ánimo, el sexo, u otros posibles factores (si son o no fumadores, etc.). Además de la variabilidad atribuible a las causas antes indicadas, el método estadístico incorpora en el análisis la variabilidad impuesta por el diseño del estudio y el procedimiento de recogida de información/datos. En efecto, usualmente no se estudia toda la población sino a una muestra (por eficiencia y economía de medios) y normalmente durante un tiempo determinado. Siguiendo con el ejemplo de la fisioterapia, lo usual es predefinir al menos 2 grupos de individuos (denominados grupo de tratamiento -que recibirá el tratamiento cuyo efecto tratamos de cuantificar- y grupo de control -al que se suministra otro tratamiento diferente o ninguno según las circunstancias concretas- ) que se intentará sean lo más homogéneos o parecidos posibles por cualquier criterio distinto del tratamiento diferencial a comparar. Definidos ambos grupos se procede a la recogida de observaciones durante un tiempo determinado dentro del cual no necesariamente todos los individuos tratados habrán alcanzado el estado de recuperación. Vemos aquí dos fuentes adicionales de variación e incertidumbre: la debida a la selección original de los individuos y consecutiva asignación a los grupos de tratamiento o control y la consecuente de ignorar cuál es el tiempo de recuperación exacto de aquellos individuos que no alcanzaron tal condición en el momento de finalizar la recogida de datos.
La estadística tradicional hace algunos supuestos simplificadores sobre la forma en que la variación se comporta representándola a través de distribuciones de probabilidad, empleando con frecuencia la denominada familia exponencial que además de reducir la variabilidad a un número reducido de dimensiones (denominadas parámetros; por ejemplo la distribución de probabilidades normal univariantes depende de la media y la varianza), presenta propiedades deseables a la hora de especificar e interpretar -a través de relaciones funcionales- cómo se alteran esos parámetros (y por tanto la distribución de probabilidad y la variabilidad que representa) en presencia de factores cambiantes.
La rica colección de métodos de análisis estadísticos que ofrece IBM SPSS Statistics y que abordamos en esta sección es consecuencia directa de la necesidad de incorporar a este análisis todas las consideraciones anteriores: las fuentes de variación del fenómeno bajo estudio, cómo se sintetizan y cómo se formula la relación entre la variable cuyo comportamiento queremos explicar y aquellas otras candidatas a explicarla que, adicionalmente, podrá ser unidireccional (la condición física del paciente afecta al tiempo de recuperación) o bidireccional (ambas variables se afectan mutuamente) o incluso multidireccional. Es relativamente sencillo concluir que eso lleva a una casuística prolija debido a que: las variables en consideración tienen distintas propiedades métricas (tiempo, frecuencia de ejercicios, condición física, sexo del individuo, edad, etc.) o que presentan modelos de variación (probabilidad) distintos (continuos, discretos, finitos, etc.) o porque hemos considerado o no todos los individuos de la población, todos los niveles de los diferentes factores y así sucesivamente.
Con estos antecedentes, pasamos ahora a describir las posibilidades de análisis que ofrece IBM SPSS Statistics.
Gráfico 1: Opciones del menú Analizar
Cualquier que sea la aproximación del análisis -estadística tradicional o aprendizaje computerizado- las primeras y últimas etapas son frecuentemente comunes:
Las primeras se dirigen a conocer los datos en relación a sus características univariantes básicas: valores o modalidades entre las que se mueven, medias o modas, frecuencias, etc, un conjunto de técnicas de carácter descriptivo que se encuentran bajo la opción Estadísticos Descriptivos. Podemos encontrar también aquí análisis de tipo bivariante incluyendo gráficos (Explorar), Tablas cruzadas y algunos gráficos para diagnosticar la adecuación de los modelos probabilísticos para representar la variación observada conforme a las prescripciones del análisis estadístico tradicional (Gráficos P-P y Q-Q).
Los análisis suelen concluir con la presentación de resultados para lo cual las opciones de Informes y Tablas son de extrema utilidad, con especial mención a esta última opción por la flexibilidad que proporciona para diseñar la tabulación de datos.
Gráfico 2: Editor de Tablas Personailizadas (vista normal)
Siguiendo los pasos del método de ANÁLISIS ESTADÍSTICO una vez concluidos los análisis descriptivos y exploratorios, se formulan las primeras hipótesis que se desea contrastar sobre los valores medios poblacionales. La opción Comparar Medias habilita estas comparaciones con opciones diferentes dependiendo del diseño del experimento en cuestión; circunscribiéndose al caso donde las diferencias entre las poblaciones comparadas son debidas a un único factor y representando la variación a través de una distribución de probabilidad normal. Si queremos considerar cómo varían las medias en presencia de más de un factor y/o covariables pasamos a la opción de Modelo Lineal General con los casos de una única variable a explicar, varias variables a explicar, medidas repetidas sobre los mismo sujetos (que reducen la variación al aplicar tratamientos diferentes a los mismos sujetos; por ejemplo: comprobar el desgaste de diferentes neumáticos montados sobre un mismo coche en un mismo recorrido y con varios coches, permite centrar el análisis en el desgaste diferencial observado en cada coche, eliminando la variación entre sujetos/coches del análisis). Contiene también la opción de Analizar los Componentes de la Varianza (cómo contribuyen los factores a la variación) para modelos donde los factores analizados no incluyen todos los niveles posibles (factores aleatorios).
Modelos lineales generalizados amplia el Modelo Lineal General permitiendo representar la variabilidad de la variable respuesta a través de otras distribuciones de probabilidad diferentes de la normal, pues esta distribución presupone una variable respuesta medida en la escala de intervalos. Así el Modelo Lineal Generalizado permite modelizar el comportamiento de frecuencias, variables dicotómicas y como su propio nombre indica acomoda una gran parte de las técnicas estadísticas como la Regresión Lineal, Regresión de Poisson, Logística y otras que aparecen como opciones del Menú Analizar pero en las que no entraremos por ser casos particulares.
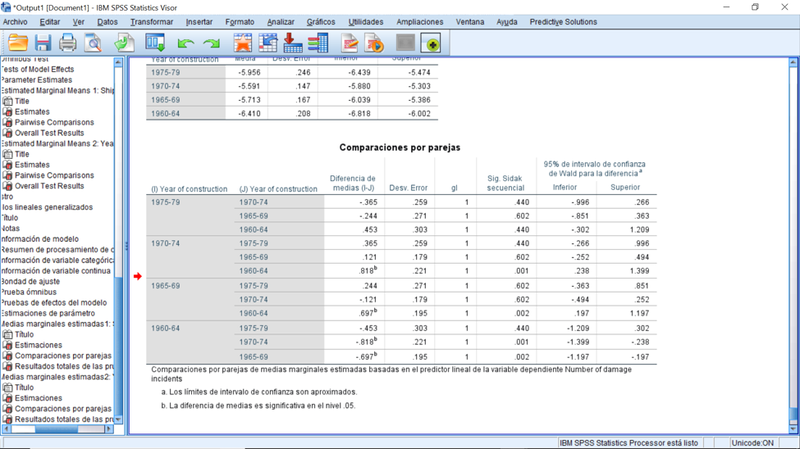
Gráfico 3: Resultado parcial del Modelo Lineal Generalizado. Comparación por pares de los efectos del año de construcción de los barcos en la tasa media de daños sufridos. (Regresión de Poisson)
Los Modelos Mixtos permiten modelizar tanto los valores medios o esperados de la distribución de probabilidad que representa la variación observada, como también su varianza de forma simultánea lo que permite acomodar diseños de experimentos donde hay presencia de covariación entre los predictores, entre otros diseños más o menos sofisticados.
Bajo la opción Correlacionar se ofrecen las opciones para analizar correlaciones entre variables dos a dos posibilitando el control de los efectos en la correlación de terceras variables, así como entre grupos de variables o multivariante. Los supuestos básicos de la correlación requieren que las variables bajo análisis se midan en la escala de intervalo pero las técnicas de análisis se generalizan fácilmente a otras escalas métricas a través de la opción Distancias.
Usualmente los datos del análisis estadístico se representan como una matriz con n filas que representan las observaciones o individuos y p columnas que representan las variables. La reducción de estas dimensiones a un subconjunto de las mismas que permita una interpretación simplificada da lugar a técnicas alternativas. Cuando se pretende reducir la dimensión de los individuos desde n a un número menor de grupos relativamente más homogéneos entramos en las técnicas de Clasificación: Análisis Clúster con varias modalidades o los métodos de Árboles y Análisis Discriminante. La diferencia entre estos últimos y la agrupación Cluster consiste en que estos métodos presuponen que la clasificación obtenida busca homogeneizar el comportamiento de una cierta variable respuesta. Por ejemplo, encontrar criterios que permitan agrupar las potenciales respuestas positivas a una determinada campaña de marketing diferenciándolas de las negativas basándonos en factores y covariables y aplicando determinadas representaciones de la variación a través de modelos probabilísticos (Discriminante) o mediante procedimientos heurísticos que entran de lleno en el Aprendizaje Computerizado (Árboles), mientras que en el Análisis Cluster no hay ningún criterio objetivo cuya homogeneización se persiga, tan sólo obtener grupos de observaciones homogéneos dentro de sí y heterogéneos entre sí. Las técnicas para reducir la dimensión de las columnas (variables) se ofrecen bajo la opción Reducción de Dimensiones: el Análisis Factorial busca explicar la correlación entre variables de intervalo a través de un número reducido de dimensiones o Factores que se construyen a partir de las variables originales; su equivalente para variables nominales se consigue mediante el Análisis de Correspondencias con su variante multivariante (Escalamiento Óptimo).
La opción Escala permite analizar las propiedades de las escalas de medida, su validez y consistencia interna a través de Fiabilidad , construir escalas continuas a partir de preferencias ordinales (Desplegamiento Multidimensional), o encontrar un conjunto reducido de dimensiones que permita replicar razonablemente la distancia o similaridad entre un conjunto de objetos como por ejemplo productos clasificados en función de sus cualidades percibidas. En puridad de términos el escalamiento multidimensional transforma la matriz de individuos * variables en una matriz de similaridad individuos * individuos y trata de replicarla empleando un número reducido de dimensiones.
La modelización del tiempo medio hasta un determinado evento (el ejemplo del tiempo hasta la recuperación referido al inicio de esta entrada) presenta particularidades específicas. Las técnicas a tal fin que ofrece PS IMAGO se reúnen bajo la opción Supervivencia llamadas así porque engloba una de las primeras técnicas al respecto: las tablas de mortalidad.
Otras opciones del Menú Analizar que cabe catalogar bajo métodos estadísticos tradicionales se recogen en la opciones de Estadísticas Bayesianas (difieren de las técnicas más clásicas en la incorporación explícita de informaciones a priori sobre ciertos parámetros bajo la forma de distribuciones de probabilidad que son ajustadas a la luz de la evidencia dando lugar a distribuciones a posteriori), Pruebas No paramétricas que relajan los supuestos sobre la representación de la variabilidad a través del modelos probabilísticos para comparar medias entre poblaciones y las Muestras Complejas que permiten diseñar muestreos en poblaciones finitas y habilitan cierto análisis de datos obtenidos bajo estos diseños muestrales diferentes del supuesto básico del muestreo aleatorio simple.
Cuando se pretende predecir el comportamiento temporal de una variable o conjunto de variables o descomponer su comportamiento estacional, la opción Predicciones presenta un conjunto de algoritmos que permiten especificar desde modelos relativamente simples hasta relativamente complejos y hacerlo de forma prácticamente automatizada.
Si muchos fenómenos presentan cierta inercia temporal en el sentido de que observaciones próximas en el tiempo tienden a ser más parecidas que las distantes, lo mismo sucede cuando se incorpora la dimensión espacial: las observaciones más cercanas espacialmente son más parecidas entre sí que las más distantes. Captar esta inercia para poder analizar la asociación entre otras variables en presencia del efecto espacial es lo que se consigue a través Modelado Espacial y Temporal que habilita también la incorporación simultánea del factor temporal.
Otras funcionalidades ofrecidas comprenden Gráficos de Control Estadístico de Calidad, Simulación y el tratamiento de variables denominadas de Respuesta Múltiple que surgen de forma natural en los cuestionarios con pregunta multi-respuesta que son representadas por conjuntos de variables (columnas) relacionadas entre sí en lugar de una única columna como es habitual. Sin olvidar las Curvas Características de Operación (COR) que permiten evaluar y comparar gráficamente la bondad de modelos de clasificación / predicción binarios.
Como métodos de APREDIZAJE COMPUTERIZADO, la opción Redes Neuronales habilita la predicción de los valores de una o más variables dependientes a partir de covariables y factores abandonando la representación probabilística de la variación y empleando métodos de optimización con validación heurística. Como decíamos al inicio, se sacrifica la comprensión de los efectos sobre la variable(s) a predecir en aras de los resultados.
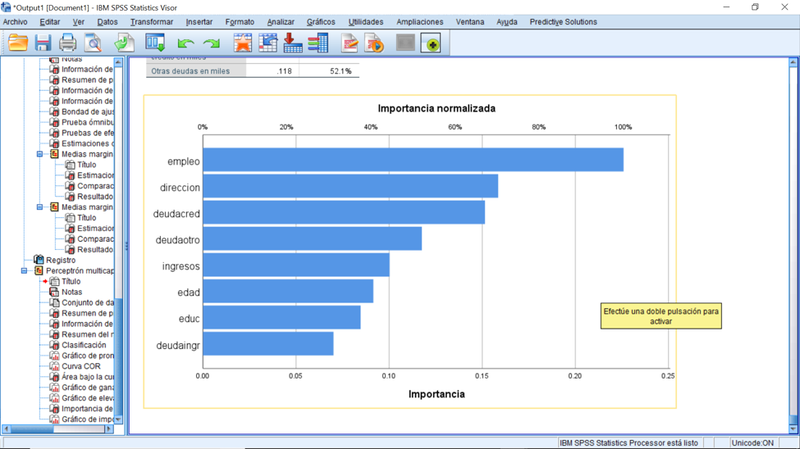
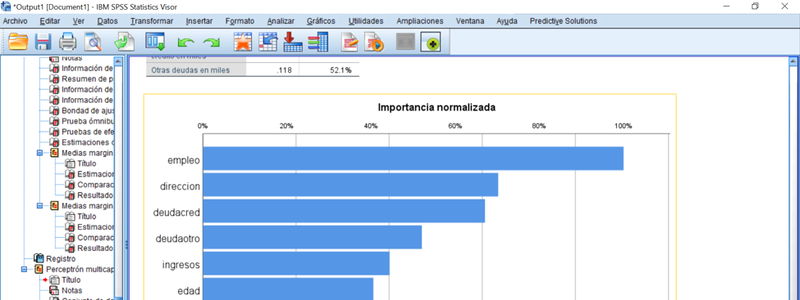
Gráfico 4: Resultado parcial de una Red Neuronal de tipo Perceptrón Multicapa mostrando la importancia de diferentes variables para predecir el impago de un crédito.
Por último, el menú analizar ofrece la opción Marketing Directo que empaqueta diversas técnicas antes referidas a objetivos de negocio bien definidos y muy frecuentes en las áreas de Marketing como segmentar, evaluar la eficacia de campañas, identificar perfiles de respuesta, etc. Lo hace además de forma más o menos automática: aplica técnicas de análisis estadístico tradicional, pero en lugar de orientarlas a la explicación de las causas de variación, se enfoca en los objetivos: perfilar, segmentar, identificar.
