Procedimientos Estadísticos
Más funcionalidad en la configuración básica
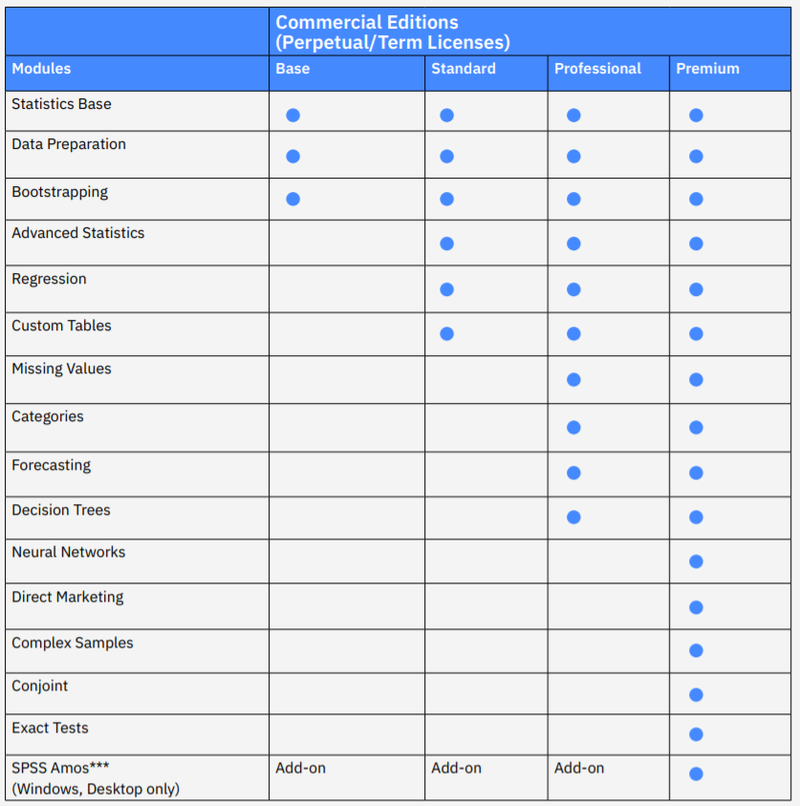
Probablemente sepa que SPSS Statistics es un paquete modular. Y también tiene diferentes configuraciones (Ediciones), que se diferencian en el conjunto de módulos. Anteriormente, la edición básica (IBM SPSS Statistics Base) incluía solo el módulo básico del paquete y ahora contiene 2 módulos ahora: Preparación de datos y Bootstrap. Por lo tanto, al adqurir una licencia básica de SPSS Statistics, obtiene más funcionalidades que nunca. La preparación de datos y el Bootstrapping contienen procedimientos útiles que no requieren conocimientos especiales para dominarlos:
- Preparación de Datos. Un conjunto de procedimientos que ayuda a preparar los datos para el análisis: identificar observaciones inválidas o atípicas, excluir variables que contienen poca información para el análisis, normalizar los datos, eliminar valores atípicos, seleccionar predictores potencialmente útiles para un modelo, realizar un agrupamiento óptimo (dividir una variable cuantitativa en categorías).
- Bootstrappping. El bootstrap es una estimación simple de los parámetros de una población que no requiere que se cumplan los supuestos de los métodos paramétricos. Los intervalos de confianza se obtienen a partir de muchas submuestras aleatorias de la muestra existente y se pueden emplear para una amplia gama de estadísticas: medias, varianzas, percentiles, proporciones, parámetros de modelos lineales, etc.
IBM SPSS Statistics versión 27 Fuente: IBM Corp., 2020
Análisis de Potencia
A partir de IBM SPSS Statistics 27, la funcionalidad básica del paquete incluye procedimientos para calcular la potencia de las pruebas estadísticas para diferentes tamaños de muestra y, a la inversa: calcular tamaños de muestra para la potencia deseada.
Estos procedimientos ayudarán a los investigadores, en la etapa de recopilación de datos, a estimar cuántas observaciones se necesitan para probar una hipótesis en particular. En general, para estimar el tamaño de la muestra, el investigador necesita elegir el tipo de efecto (por ejemplo, puede ser una hipótesis sobre el valor medio, sobre la proporción, sobre el coeficiente de correlación o sobre la influencia del predictor en el modelo de regresión), indicar las expectativas del tamaño del efecto en valores estandarizados o absolutos, definir el nivel de significación al que se debe rechazar la hipótesis nula, y la potencia deseada (es decir, la confianza de alcanzar el umbral del nivel de significación si el efecto del tamaño especificado está realmente presente en la población general). El resultado da una estimación del tamaño de muestra requerido. Puede actuar en orden inverso: establezca el tamaño de muestra planificado y obtenga una estimación de la potencia, es decir, nuevamente, la probabilidad de rechazar con éxito la hipótesis nula si el efecto deseado está realmente presente en la población general.
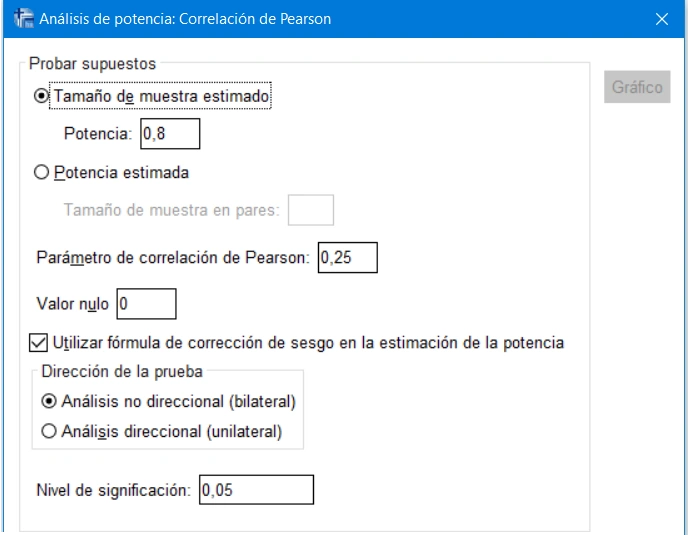
Diálogo de procedimiento de análisis de potencia para evaluar la correlación de Pearson. Potencia requerida: 0.8, factor de muestreo esperado 0.25, hipótesis del coeficiente 0, prueba bilateral, nivel de significancia 0.05. IBM SPSS Statistics 27
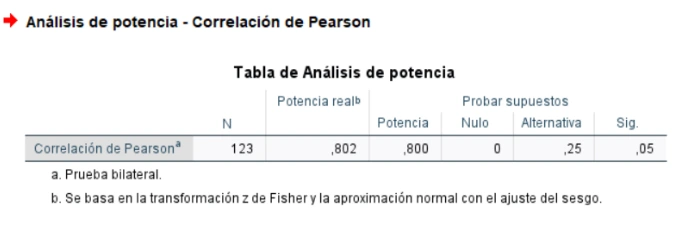
El resultado del procedimiento análisis de potencia para evaluar la correlación de Pearson. El tamaño de muestra requerido para los parámetros dados (supuestos de prueba) es 123. La potencia real con este tamaño será 0,802. IBM SPSS Statistics 27
Los cálculos de tamaño / potencia de la muestra están disponibles para los siguientes tipos de hipótesis:
- Test t para la media de una muestra
- Test t para muestras apareadas
- Test t para muestras independientes
- ANOVA de un factor
- Proporción para una muestra binomial.
- Diferencia de Proporciones para muestras binomiales apareadas
- Diferencia de Proporciones para muestras binomiales independientes
- Coeficiente de correlación de Pearson para una muestra
- Coeficiente de correlación por rangos de Spearman para una muestra
- Coeficiente de correlación parcial de Pearson
- Coeficientes de la Regresión Lineal Univariante
Tamaño del efecto
Se agregó el cálculo de la medida del tamaño del efecto estandarizadas a los procedimientos de comparación de medias y ANOVA de una vía. Cuando contrastamos una hipótesis estadística, considerando los estadísticos al efecto y su significación, estamos tratando de probar el hecho de la presencia de un efecto (diferencias, diferencias, correlaciones).
A diferencia de la significación estadística, las medidas de efectos no intentan probar la existencia de un efecto, sino estimar su tamaño. El efecto se puede medir en términos absolutos o se puede estandarizar. Estamos acostumbrados, por ejemplo, a una medida tan estandarizada como el coeficiente de correlación de Pearson. Con relativamente menor frecuencia trabajamos con medidas estandarizadas de diferencias de medias. Las medidas estandarizadas de efecto para promedios hacen posible hablar de diferencias como "menores", "moderadas", "grandes", sin entrar en unidades específicas. Mientras tanto, las medidas de efecto para las medias juegan un papel importante en la investigación moderna. Con su ayuda, en base a los resultados de investigación publicados, se realizan los metanálisis y se derivan estimaciones más confiables de ciertos fenómenos.
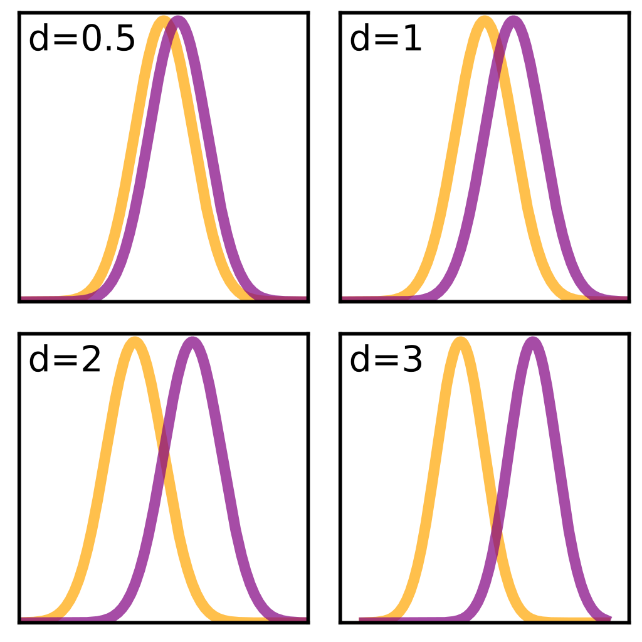
Visualización de diferentes valores d de Cohen usando el ejemplo de diferencias en las medias de dos distribuciones normales. Fuente: Wikipedia, Tamaño del efecto
En IBM SPSS Statistics, el tamaño del efecto para los promedios se estimó previamente en algunos procedimientos de modelo lineal "avanzados", pero a partir de la versión 27, las pruebas más populares para los promedios del módulo principal también pueden devolver una estimación del tamaño del efecto y su intervalo de confianza del 95%. Los cambios afectaron a los siguientes procedimientos:
- Test t para la media de una muestra
- Test t para muestras apareadas
- Test t para muestras independientes
- ANOVA de un factor
Para la diferencia de 2 medias y contrastes, los efectos se calculan en función de la diferencia normalizada de medias:
- D de Cohen
- Corrección de Hedges (g)
- Delta de Glass
Para un factor en ANOVA, los efectos se calculan con base en la proporción de la varianza explicada:
- Eta al cuadrado
- Epsilon al cuadrado
- Omega-cuadrado efectos fijos
- Omega-cuadrado efetos aleatorios
Salida de una estimación del tamaño del efecto cuando se prueba la hipótesis sobre el valor medio. IBM SPSS Statistics 27
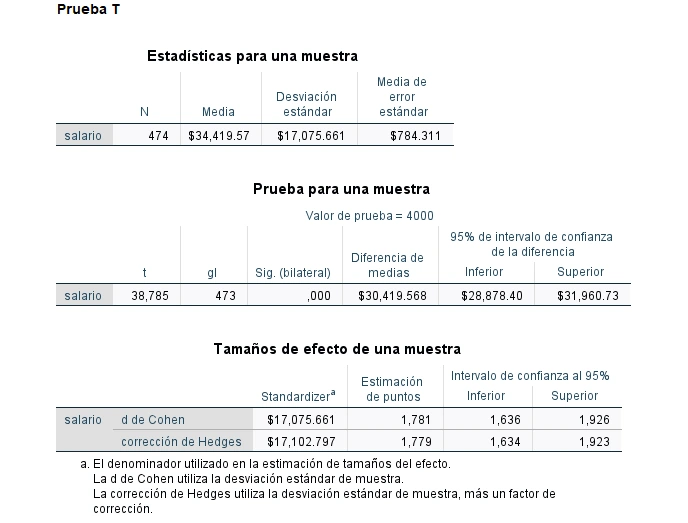
Las estimaciones del tamaño del efecto son Cohens'd y Hedges'g y sus intervalos de confianza en el procedimiento del test t para la media. IBM SPSS Statistics 27
Kappa ponderado de Cohen
El estadístico kappa de Cohen es una medida común de la consistencia de las dos clasificaciones. Se puede utilizar para medir cómo de parecidos son dos expertos en la clasificación de objetos en un número determinado de grupos. O, por ejemplo, en qué medida la clasificación realizada por el modelo predictivo corresponde a clases reales de objetos. El estadístico kappa de Cohen ha estado disponible en SPSS Statistics durante bastante tiempo. Se encuentra en el cuadro de diálogo para calcular tablas de contingencia.
En la versión 27, apareció el kappa ponderado de Cohen, al calcular el orden de las categorías. ¿Qué quiere decir?
Para un Kappa simple, para cada observación específica, solo importa el hecho de la coincidencia o no coincidencia de su clase según las dos fuentes de clasificación. Sin embargo, si las clases están ordenadas de alguna manera, entonces es obvio que un posible error (desajuste de categorías) tiene su propio peso, por así decirlo. La asignación de un objeto por diferentes expertos a clases adyacentes es menos inconsistente que la definición de objetos a clases en diferentes extremos de la escala. El kappa ponderado de Cohen permite tener esto en cuenta y "penalizar" las inconsistencias de mayor magnitud. En consecuencia, el resultado (en realidad, el valor de kappa) diferirá del kappa no ponderado. Y en caso de que se trate de categorías ordenadas, la versión 27 de SPSS Statistics ofrece una medida más precisa de la consistencia de las clasificaciones.
Cuadro de diálogo del procedimiento Kappa ponderado de Cohen. IBM SPSS Statistics 27
Adiciones a varios procedimientos
Nuevas funciones en el procedimiento MATRIX. Los usuarios experimentados de SPSS pueden utilizar el lenguaje matricial de SPSS para desarrollar nuevos procedimientos con cálculos basados en los principios del álgebra lineal. Este idioma no tiene interfaz de diálogo. Para aquellos que trabajan con el lenguaje MATRIX, será interesante saber que en IBM SPSS Statistics 27 el lenguaje MATRIX agrega funciones para trabajar con distribuciones de probabilidad y números aleatorios. Anteriormente, estas funciones requerían que recurriera al comando COMPUTE directamente en el conjunto de datos.
Control de estimaciones de parámetros de distribución en la prueba de Kolmogorov-Smirnov. Se han modificado los diálogos y comandos de la sintaxis de la prueba de Kolmogorov-Smirnov utilizados para evaluar la correspondencia de la distribución real de una variable con una distribución determinada. Diálogos y sintaxis modificados en los procedimientos no paramétricos antiguos (NPAR TESTS) y nuevos (NP TESTS). Ahora, en cada uno de ellos, puede especificar si desea estimar los parámetros de distribución a partir de los datos o establecerlos. Y en el caso de una estimación basada en datos, indique el número de muestras para la estimación de Monte Carlo y el intervalo de confianza deseado para la significación estadística.
Regresión cuantílica o por cuantiles. El procedimiento de regresión cuantílica permite ahora especificar una cuadrícula de cuantiles a estimar. Se ha vuelto más fácil especificar la necesidad de evaluar varios cuantiles a la vez, por ejemplo, de 0,10 a 0,9 con incrementos sucesivos de 0,1.
Gráficos y presentación de resultados
Nuevas opciones de formato para tablas
A partir de la versión 27 de SPSS, el usuario puede solicitar la construcción de una matriz de correlación, donde los elementos simétricos sobre la diagonal principal no se duplican: el triángulo superior de la matriz permanece vacío. Esto requiere marcar la casilla en el cuadro de diálogo actualizado. Además, puede hacer que la matriz sea aún más compacta eliminando los elementos de la diagonal principal que no contienen información útil. También se han realizado las modificaciones correspondientes al comando de sintaxis CORRELATIONS: tiene nuevas palabras clave responsables del tipo de matriz de correlación.
Para los procedimientos populares para construir tablas de frecuencia y tabulaciones cruzadas, también es posible hacer que la salida sea más compacta con un solo clic, y las tablas resultantes están listas para su publicación. Esta es la casilla de verificación Crear tabla de estilo APA. APA es un acrónimo de American Psychological Association, que ha desarrollado una política de estilo de publicación ampliamente aceptada por la comunidad científica: la tabla resultante aparece limpia de elementos auxiliares y encabezados de filas y columnas, y las estadísticas reciben nombres compactos.
Nuevos parámetros OUTPUT MODIFY
El comando OUTPUT MODIFY se introdujo en la versión 22 de SPSS y es una herramienta poderosa para ajustar los resultados. Con su ayuda, puede formatear la salida sin recurrir a scripts y permanecer dentro de la sintaxis de SPSS. Este comando se expandió en la versión 27, y ahora es posible rotar adicionalmente la tabla (es decir, realizar el llamado pivoteo), agrupar / desagrupar los encabezados de fila y columna (es decir, hacer que la tabla sea más simple en estructura, y esto preferiblemente si queremos, por ejemplo, exportarlo a Word), así como buscar y transformar columnas que contengan estadísticas específicas. Esto se hizo solo para las tablas de tabulación cruzada y de frecuencia de estilo APA, pero con el comando avanzado, los usuarios también pueden transformar tablas generadas por otros procedimientos.
Gráfico de burbujas
El generador de gráficos tiene una nueva plantilla incorporada para crear gráficos de burbujas. Estos son diagramas de dispersión, en los que puede reflejar la relación de 4 variables a la vez: dos variables cuantitativas establecen los ejes del gráfico, otra variable cuantitativa establece el tamaño de un punto (o, en este caso, una burbuja). Y con la variable categórica, las burbujas se pueden colorear por categoría. SPSS había permitido dibujar estos diagramas durante mucho tiempo, pero esto requería el uso de la GPL (Lenguaje de producción gráfica) incorporada. Ahora puede crear un diagrama necesidad de código.
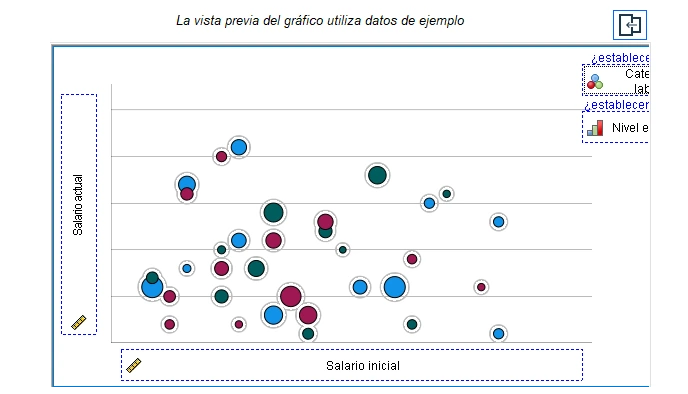
Cuadro de diálogo del generador de gráficos con configuraciones para el tamaño de burbuja para el diagrama de dispersión. IBM SPSS Statistics 27
Más opciones para formatear gráficos
En las opciones de SPSS, en la configuración predeterminada para formatear gráficos, se agregó una vista previa de los gráficos. Al cambiar una u otra configuración, el usuario ve inmediatamente cómo, aproximadamente, afectará la apariencia del diagrama futuro.
Aparecen varios estilos de gráficos preestablecidos a la vez, entre los cuales es conveniente cambiar. El estilo deseado se puede establecer en la configuración global del sistema y se puede seleccionar individualmente en el cuadro de diálogo del generador de diagramas. Por ejemplo, sabiendo que va a publicar su gráfico en blanco y negro, puede elegir el estilo preestablecido Publicación Gris. Al mismo tiempo, por supuesto, aún puede aplicar una plantilla de diseño desde un archivo separado.
Tamaños de fuente
Se han agregado botones para aumentar / disminuir rápidamente los tamaños de fuente en el editor de salida en los paneles para editar gráficos y elementos de tabla.
Interfaz del sistema y funcionalidad auxiliar
Tema de interfaz ligera
Por supuesto, esto es inmediatamente evidente. El nuevo SPSS parece un poco extraño al principio, pero se acostumbra rápidamente al nuevo diseño. El tema SPSS Light se ha vuelto un poco más ligero, sin elementos innecesarios, más "cuadrado", en general, moderno. Si le gustó trabajar con uno de los temas anteriores, puede establecerlos en la configuración.
A través de la búsqueda
Todas las barras de herramientas ahora tienen un botón de paso de forma predeterminada. ¿Cómo funciona? A medida que introduce texto en la barra de búsqueda, SPSS busca el término entre menús y temas de ayuda en línea. Entonces, por ejemplo, cuando ingrese "correl", aparecerá en la ventana una lista de procedimientos (cuadros de diálogo) con la palabra "correlación" en sus nombres, así como secciones de ayuda, que incluyen ejemplos de estudios de caso que hablan sobre análisis de correlación. Al seleccionar el elemento de lista apropiado, se abre inmediatamente el cuadro de diálogo correspondiente o un navegador con una página de ayuda.
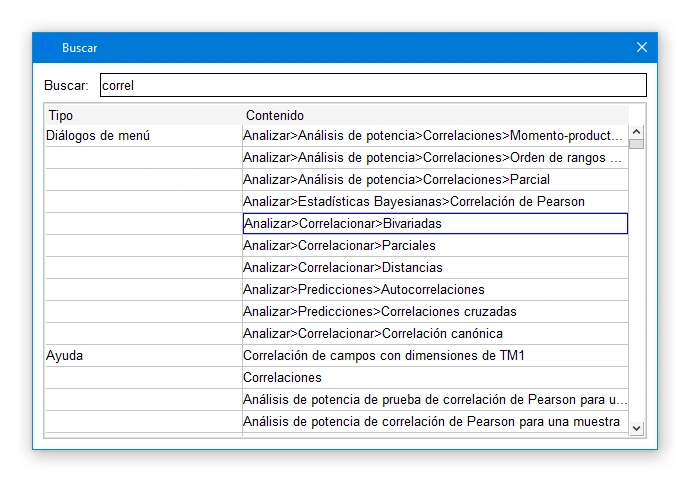
El cuadro de diálogo de búsqueda IBM SPSS Statistics 27
Recuperar archivos automáticamente
Se agregó la función de recuperación automática de datos por pérdida accidental durante la terminación anormal de la aplicación o el sistema operativo. De forma predeterminada, la función realiza una copia de seguridad de los archivos de salida, la sintaxis y los datos no guardados cada 10 minutos. El intervalo se puede configurar. Si es necesario, se puede desactivar la recuperación automática.
Feedback
A veces, mientras se trabaja con una aplicación, surgen ideas sobre cómo se puede mejorar. Ahora en SPSS es posible dar retroalimentación/feedback rápida sin distraerse demasiado del trabajo. Simplemente seleccione el elemento del menú Enviar comentarios y coloque algunas palabras que le gustaría cambiar en SPSS. Esto ayudará a los desarrolladores a mejorar las nuevas versiones del producto. Junto a esta sección está el formulario de notificación de errores.
Diálogo de apertura de archivo nativo para macOS
Los usuarios de Mac en la nueva versión de SPSS se deleitarán con los cuadros de diálogo de selección de archivos familiares para los sistemas Macintosh. En versiones anteriores, estos diálogos eran muy diferentes de los estándar como resultado de la adaptación de la interfaz original de Windows a la plataforma Mac.
Otro
Python 3.8.2 incluido
Se está implementando una versión más moderna del intérprete de Python, 3.8.2, con el nuevo SPSS. Por supuesto, junto con esta versión, se instalan las correspondientes bibliotecas adaptadas, proporcionando la integración de Python y SPSS. Si prefiere utilizar un intérprete más antiguo (incluido Python 2), entonces, como antes, esto puede configurarse adicionalmente.
Pantalla de bienvenida online
Desde la pantalla de bienvenida, que se abre por defecto cada vez que inicia el programa, es conveniente abrir los últimos archivos de trabajo o archivos de ejemplo. También contiene enlaces a los recursos de Internet más populares relacionados con SPSS. En SPSS 27, la pantalla pudo extraer noticias, actualizaciones de productos y otra información relevante del sitio de IBM.
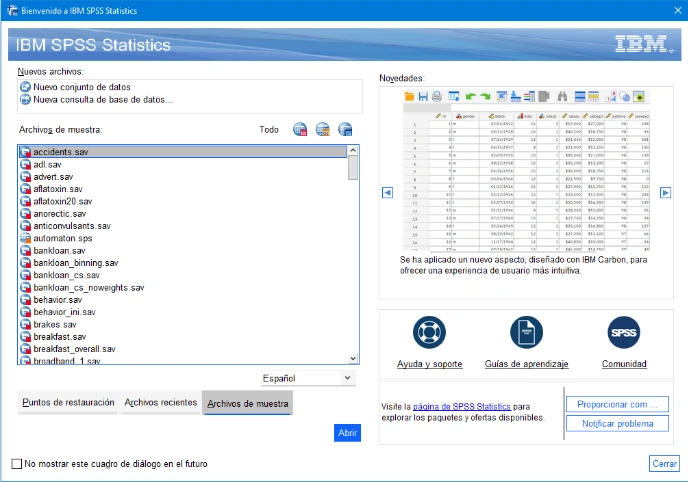
Diálogo de bienvenida de IBM SPSS Statistics 27
Configuración de privacidad
Ha aparecido una nueva pestaña en la configuración del producto: Privacidad. Aquí puede habilitar o deshabilitar la carga de información para la pantalla de bienvenida a través de Internet, así como habilitar o deshabilitar el intercambio automático de información con el fabricante (IBM) sobre estadísticas de uso del producto y posibles errores.
Con la ayuda de Predictive Solutions, puede convertirse en usuario de la nueva versión de IBM SPSS Statistics y, lo más importante, recibir un soporte técnico competente. Si tiene alguna pregunta, escríbanos a: info@predictivesolutions.es.
