Bajo este nombre, denotamos varios procesos ejecutables de forma interactiva o por lotes, para identificar y tomar medidas correctivas sobre datos que son incompletos, incorrectos, inapropiados o irrelevantes. En otras palabras, son procesos dirigidos a garantizar la calidad de los datos: que sean correctos y significativos y que conformen una representación "fiel" de la realidad que idealizan. IBM SPSS Statistics proporciona varias rutinas para ese fin:
- Validar datos
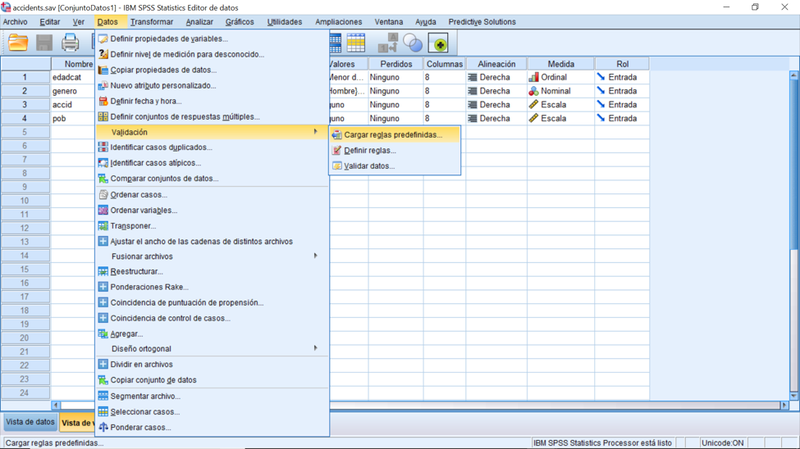
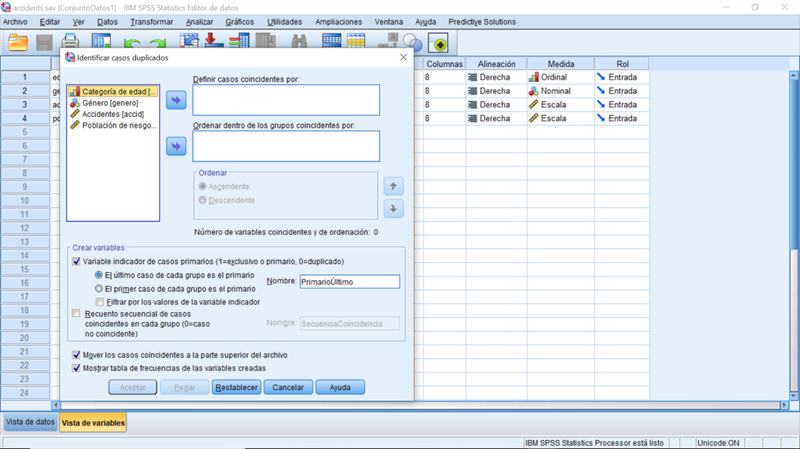
- Identificar casos duplicados
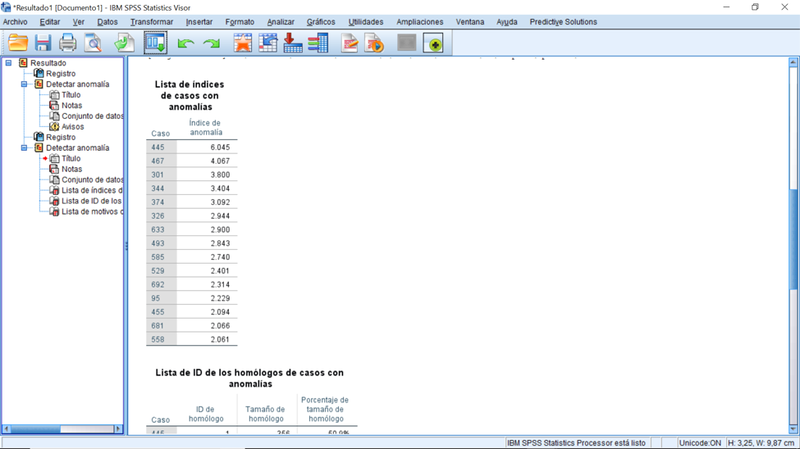
- Identificar casos atípicos
- Reemplazar e imputar valores perdidos
Datos > Validación
IBM SPSS Statistics permite la definición y aplicación de reglas de validación de datos que son la expresión de restricciones que los datos deben satisfacer tales como que las variables sean de un tipo particular (cadenas y no numéricas), que tomen valores dentro de un rango predefinido (no puede haber individuos mayores de 105 años), o que estén relacionadas de alguna manera (no pueden tener licencia de conducir los menores de 18 años), etc.
Datos > Identificar Casos Duplicados
Un caso duplicado es un caso redundante. Se repite dentro del conjunto de datos, pero no corresponde a una instancia real repetida. Su presencia durante el análisis es engañosa, ya que sobrepondera la contribución real de esa instancia. IBM SPSS Statistics proporciona un proceso intuitivo para gestionar estos casos que permite su identificación y tratamiento posterior.
Datos > Identificar Casos Atípicos
La identificación de casos inusuales recae en la intersección entre la auditoría y la validación de datos, es decir, puede considerarse un paso del proceso de limpieza de datos o parte de la fase de análisis exploratorio de datos. De todos modos, esta opción de menú proporciona un procedimiento para identificar casos inusuales genéricos, siendo el carácter "inusual" determinado por su posición relativa a la distribución de la nube de observaciones. Este procedimiento agrupa los datos en grupos homogéneos y luego mide la distancia de cada caso en relación con la posición promedio del grupo al que pertenece, midiendo la contribución de cada variable considerada en el análisis a dicha "distancia“; contribuciones que pueden convertirse en las razones de que cada caso sea considerado anómalo si van más allá de ciertos umbrales determinados empíricamente según la variabilidad dentro de su grupo de pertenencia.
Datos > Analizar valores perdidos
Cuando algunos de los casos (filas) bajo análisis no están completamente informados (hay algunas columnas o campos con información faltante), tenemos datos perdidos o faltantes. Puede haber varias razones para eso y nos referiremos aquí al caso más simple: donde debería haber información presente pero no es así. A priori, menos observaciones significa menos información y, por lo tanto, la solidez del análisis se reduce o incluso se ve comprometida. Además, algunos algoritmos específicos simplemente no funcionan con datos faltantes lo que inviabiliza su uso para el análisis.
IBM SPSS Statistics ofrece varios procedimientos para manejar estas situaciones: permite el análisis de datos perdidos con el objetivo de identificar patrones potenciales dentro de los datos asociados información faltante (Analizar> Análisis de valores perdidos) que al mismo tiempo que proporciona métodos para imputar valores perdidos; o procedimientos más avanzados, no cubiertos en esta entrada, como los de Analizar> Imputación múltiple que admite la imputación multivariante de valores perdidos.
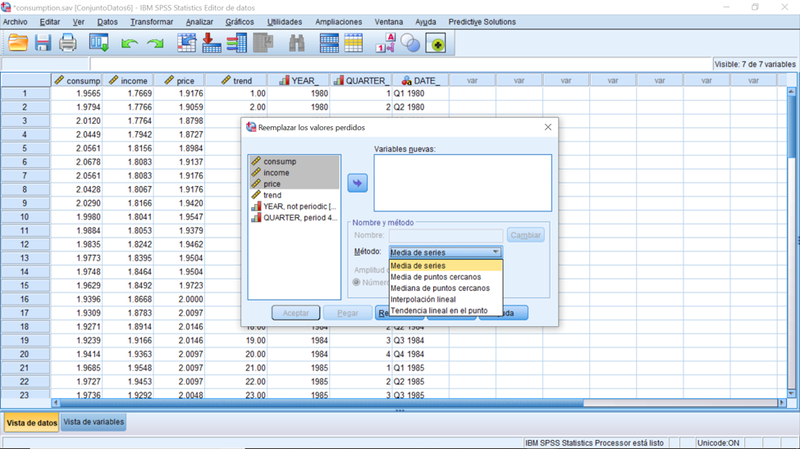
Datos > Remplazar valores perdidos
Específicamente concebido para el trabajo con series temporales, donde las observaciones se ordenan en secuencia correspondientes a intervalos iguales de tiempo, SPSS IBMS Statistics ofrece un procedimiento relativamente simple para reemplazar la información que falta, substituyéndola por valores medios o a través de interpolación lineal.