De forma sumaria, esto es lo nuevo en IBM SPSS Statistics 28:
- Procedimientos estadísticos de meta-análisis que le ayudarán a combinar estimaciones de varios estudios -que responden a cuestiones de investigación semejantes- en una evaluación única e identificar fuentes de variación entre dichos estudios. A su disposición están los procedimientos para combinar los valores de los efectos para variables respuesta numéricas y binarias, así como meta-regresión. El meta-análisis, puede realizarse directamente sobre los datos brutos o sobre estimaciones con tamaños de efecto pre-calculados.
- El libro de trabajo o "workbook" es un nuevo modo de funcionamiento del programa que incorpora las instrucciones escritas en el lenguaje de comandos (sintaxis) y los resultados generados en un documento interactivo común. Al trabajar con este documento, el usuario puede actualizar selectivamente los fragmentos de código, modificando la sintaxis y recalculando el resultado correspondiente. Resulta muy conveniente durante las etapas de análisis exploratorio.
- Visualizar el análisis de potencia mediante gráficos. Una opción adicional para establecer una rango de valores de potencia al calcular el tamaño de la muestra.
- Método de dispersión conocido como “sesgo relativo al precio (PRB) “.
- Así como adiciones en una serie de procedimientos:
- derivación explícita de los resultados de probar una hipótesis unilateral en procedimientos del t-criterio.
- comparación de los principales efectos dentro de las categorías del factor en los procedimientos GLM y UNIANOVA;
- Cambiar el orden básico de las categorías al establecer contrastes en los procedimientos DE REGRESIÓN LOGÍSTICA y COXREG;
- comparación de los principales efectos dentro de las categorías del factor en los procedimientos GLM y UNIANOVA;
- Cambiar el orden básico de las categorías al establecer contrastes en los procedimientos DE REGRESIÓN LOGÍSTICA y COXREG;
- Un nuevo diagrama, mapa de relaciones, para ilustrar las relaciones entre variables categóricas a través de un gráfico de red: nodos (categorías de variables) y ejes (relaciones).
- Búsqueda de texto detallada, que se ejecuta sobre los cuadros de diálogo, temas de ayuda, referencias de sintaxis, case studies.
- Barra lateral en el Editor de tablas para un acceso rápido a varias opciones de diseño.
- Modo de visualización en alto contraste.
- Cambios en el soporte para R, Python, y más extensiones instalables (Extensiones)
- Cambios en el activador de licencias
- Amplia la capacidad de exportar resultados
- Ocultar observaciones filtradas
- Generador avanzado de gráficos
En detalle:
Meta-análisis
El meta-análisis es una metodología científica reconocida que permite combinar los resultados de diferentes estudios independientes alrededor de cuestiones semejantes. Tal generalización se hace para obtener estimaciones estadísticas más robustas de los parámetros de interés, y estudiar la influencia de los estudios individuales en la evaluación final, incluyendo el denominado sesgo de publicación: la preferencia por publicar sólo resultados científicos en los que se obtuvieron resultados significativos de pruebas de hipótesis. El meta-análisis puede incluir:
- resultados presentados en publicaciones científicas,
- los resultados de estudios obtenidos de forma independiente por diferentes grupos de investigación en el marco de un gran proyecto,
- resultados obtenidos en estudios anteriores y posteriores del mismo fenómeno.
En el meta-análisis la unidad de observación es cada estudio individual. La necesidad de meta-análisis más frecuente se manifiesta en las áreas de investigación médica, psicología y educación, donde los resultados de los estudios individuales se alcanzan usualmente a partir de muestras relativamente pequeñas con conclusiones ocasionalmente contradictorias, por lo que se desea estimar con mayor confianza la influencia de un factor en particular, así como identificar los factores (manifestados en las características de los estudios individuales) que conducen al sesgo en las estimaciones. Por ejemplo, al investigar el efecto a largo plazo de un fármaco en la reducción de la presión arterial, es importante resumir la experiencia de su uso en diferentes instituciones entre diferentes grupos de pacientes, y obtener una evaluación sintética del grado de exposición al fármaco, un intervalo de confianza generalizado de esta evaluación, así como identificar aquellos casos en los que las estimaciones son muy diferentes de la mayoría.
SPSS Statistics 28 aporta un conjunto amplio de técnicas de meta-análisis que comprenden procedimientos para variables continuas y binarias, así como la regresión del tamaño del efecto sobre covariables presentes en los estudios, donde los valores precalculados del efecto en estudios individuales se convierten en variables dependientes, y las características de los estudios (los llamados moderadores) se convierten en covariables (el procedimiento "Meta-análisis: Regresión", META REGRESIÓN)
Si por ejempl, está interesado en una estimación generalizada del efecto de la vacunación sobre la incidencia de complicaciones de la enfermedad, y tiene estadísticas detalladas de diferentes centros / estudios sobre grupos de prueba y control, puede aplicar el procedimiento META-BINARY. Si los datos de investigación que tiene presentan la forma de una magnitud de efecto (por ejemplo, odds ratio), debe utilizar el procedimiento META ES BINARY.
Se han añadido nuevos procedimientos para realizar el metanálisis al módulo base de IBM SPSS Statistics.
Combinación de sintaxis y resultados en el modo Libro de trabajo (workbook)
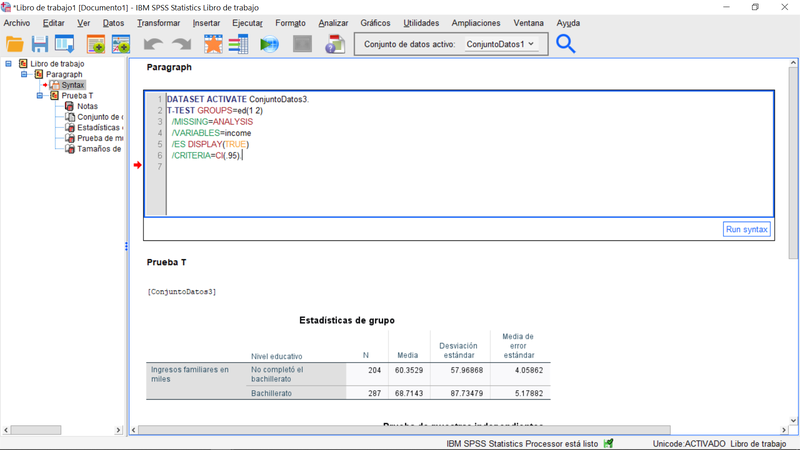
La sintaxis de SPSS sirve para registrar y automatizar las acciones realizadas en forma de código de programación simple, y el flujo de resultados (salida). A lo largo de los años se han manenido como dos entornos (ventanas) diferentes de la interfaz de usuario. A partir de la versión 28, es posible combinar estos dos componentes en un solo documento, denominado “Libro de Trabajo” o “workbook”. Este modo es ideal para el análisis incremental de datos típico de las fases exploratorias.
Dentro de un libro de trabajo se pueden colocar fragmentos de sintaxis, ejecutarlos y ver el resultado en el siguiente "párrafo" del mismo documento en lugar de otra ventana. Al cambiar y volver a ejecutar la sintaxis, el usuario visualiza los resultados actualizados sobre el mismo documento. Así, la inmediata asociación visual entre los comandos ejecutados y los resultados generados, simplifica la navegación y agiliza el proceso analítico.
El modo clásico, donde la sintaxis y la salida están separadas, también se conserva, ya que la combinación de código y resultados en el libro de trabajo no siempre será la mejor opción. Por ejemplo, no todos los destinatarios de resultados estarán interesados en ver la sintaxis. Los archivos de sintaxis tradicionales también seguirán siendo el medio de comunicación más conveniente y conciso dentro del equipo de investigación para transmitir información sobre la secuencia de acciones en el paquete, así como una herramienta indispensable para automatizar el análisis repetitivo, cuyo resultado no se envía al archivo de salida spss, sino a archivos de datos u otros formatos. Sin embargo, no hay duda de que el Libro de Trabajo encontrará sus seguidores. El modo libro de trabajo es alternativo al tradicional de sintaxis y resultados por separado, y debe de ser activado en el menú principal: Editar-> Opciones.
Libro de Trabajo
La asignación interactiva de código y resultados no es la única ventaja del libro de trabajo pues el usuario conserva la capacidad de editar los resultados como en un archivo de resultados tradicional.
Visualización de los resultados del análisis de potencia
El análisis de potencia es el punto de partida en la planificación de todo estudio estadístico. Permite, incluso antes de la recogida de datos, evaluar la probabilidad de que el estudio detecte un efecto estadísticamente significativo para un tamaño de muestra particular, bajo el supuesto de que ese efecto deseado y postulado existe realmente en la población general.
Al decidir el tamaño de la muestra, es útil evaluar un conjunto de escenarios con diferentes niveles de potencia del contraste. Sin necesidad de reducir sensiblemente la potencia de un contrase, es tal vez posible reducir el número de observaciones y los costes de recogida de datos. IBM SPSS Statistics 28 permite establecer una rango de valores de potencia para evaluar rápidamente dichos escenarios y mostrar el resultado no solo en forma tabular, sino también a través de un gráfico de curvas de potencia.
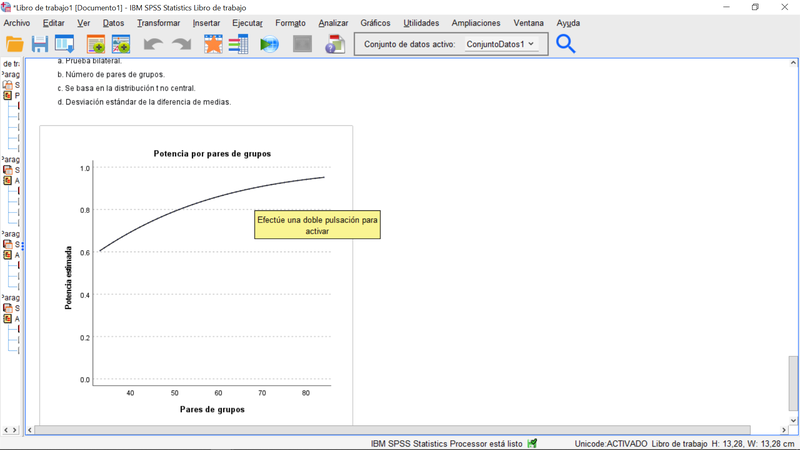
Gráfico de potencia, test t
Adiciones al procedimiento de estadísticas de la razón
Las estadísticas de la razón (cocientes) tienen varios casos de uso. Por ejemplo, en el negocio de valoración de activos inmobiliarios, se utilizan para estudiar la relación entre el precio de valoración de la propiedad y el precio de la venta real. Los reguladores de la industria pueden incluso establecer ciertos estándares para informar sobre este tipo de proporciones. Uno de estos requisitos es el cálculo del coeficiente de variación de la evaluación en función del precio del objeto (sesgo relativo al precio, PRB). Estos estadísticos y su intervalo de confianza ahora se pueden calcular directamente a través de los cuadros de diálogo SPSS. Otros cambios en este procedimiento se refieren a la exclusión del diálogo del coeficiente de variación basado en la mediana (y el coeficiente de variación basado en el promedio se designa COV), así como la salida a las tablas del número de objetos en base a los cuales se obtuvieron las estadísticas.
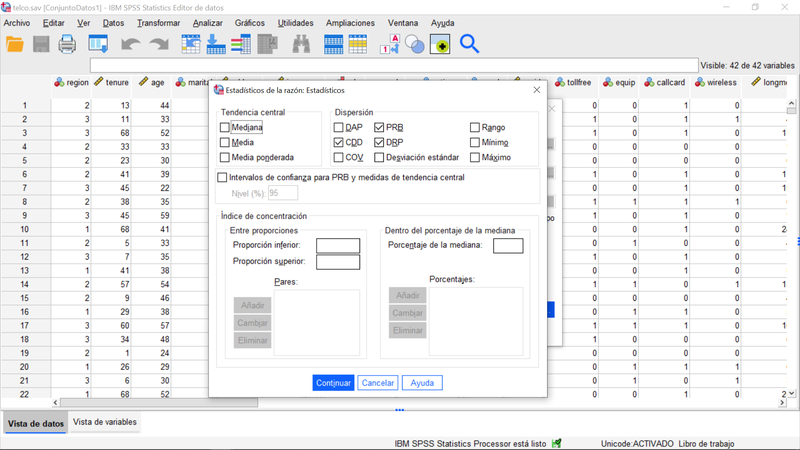
Estadísticas de la razón
Mapa de relaciones
IBM SPSS Statistics 28 introdujo una nueva forma de visualizar las relaciones entre variables categóricas. Consiste en un mapa de relaciones (otros nombres son web, mapa de conexiones). En este diagrama, los vértices ilustran categorías individuales de variables, y el grosor de las líneas de conexión es proporcional al número de observaciones que tienen una combinación de categorías conectadas.
Un mapa de relaciones puede ayudar a identificar rápida y visualmente combinaciones típicas y categorías infrecientes, e ilustrar las relaciones observadas entre varias variables de forma simultánea.
El usuario encontrará el cuadro de diálogo del nuevo procedimiento en el menú Gráficos... Mapa de relaciones. En el cuadro de diálogo, puede controlar la composición de las variables incluidas en el análisis, los rangos de grosor del conector y tamaños de icono de vértice, y la orientación del gráfico.
Diversas adiciones a los procedimientos existentes
Se han introducido pequeñas alteraciones los procedimientos para calcular los criterios t clásicos, incluyendo contrastes unilaterales ("mayor" o "menor").
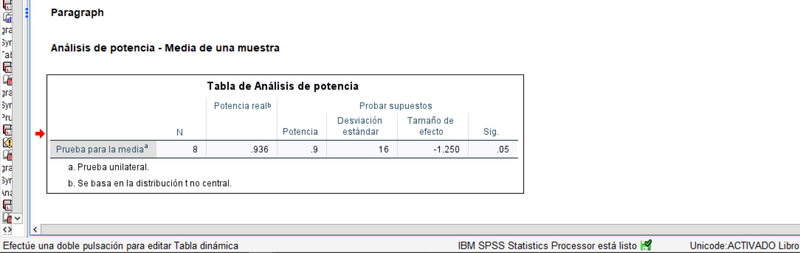
Test t unilateral
En los cuadros de diálogo Modelo Lineal General (GLM) y Análisis de varianza Unidimensional (UNIANOVA), se puede solicitar la comparación de efectos principales simples (Comparar efectos principales simples) en la sección Medias EM. Así, el usuario puede solicitar una comparación de los principales efectos del factor dentro de los niveles (categorías) de otro factor.
Se han realizado mejoras cosméticas en cuanto a la configuración del contraste en los procedimientos de regresión logística (REGRESIÓN LOGÍSTICA) y regresión de Cox (COXREG):
- Se han cambiado los valores predeterminados en contraste con la categoría de referencia (la primera categoría está ahora en primer lugar) y, en consecuencia, se ha cambiado el orden de los botones Primero y Último.
- Se ha añadido una característica de la última categoría a la lista de covariat categórica.
Buscar
Introducido por primera vez en la versión 27, la función de búsqueda se expande en la versión 28:
- se introducen sus nombres alternativos (alias) para los términos de búsqueda, con la ayuda de los cuales se incrementan las posibilidades de detectarlos incluso sin una coincidencia directa con el título en sí;
- se incluye la búsqueda sobre el contenido de los cuadros de diálogo. Puede encontrar todas las menciones a las estadísticas que le interesan, incluso si su nombre no está incluido en el encabezado del menú. Por ejemplo, la imagen siguiente muestra un ejemplo de cómo encontrar todos los diálogos en los que se incluye el término "meta".
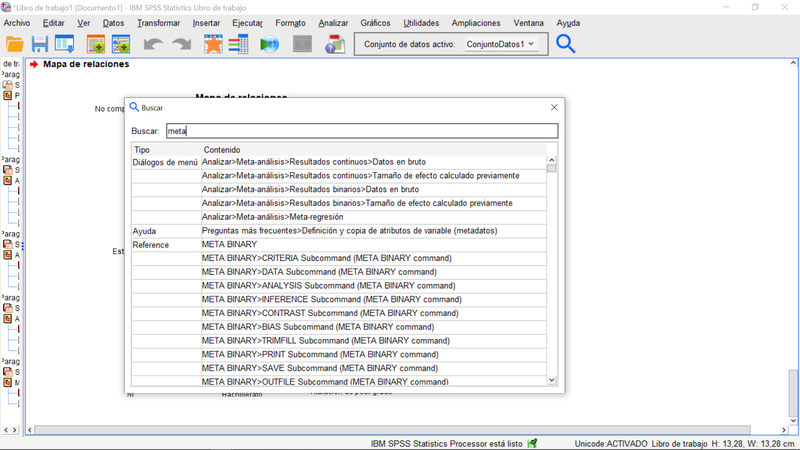
Ejemplo de búsqueda
Barra lateral del editor de tablas
En el editor de tablas del visor de resultados, se introduce una barra lateral contraíble a la derecha de la tabla, duplicando la configuración previamente disponible a través del menú superior. Ahora puede moverse rápidamente entre diferentes configuraciones de tabla, haciendo menos clics del mouse al editar y comprobar el efecto de los cambios realizados en tiempo real.
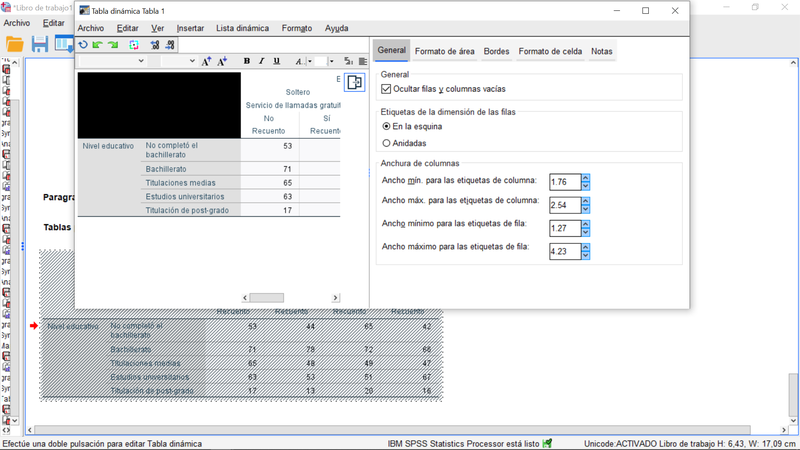
Editor de tablas
Tema de contraste - visualización
SPSS v28 es compatible con el modo de contraste, que se activa automáticamente si el contraste alto está habilitado en el sistema operativo (Windows y Mac).
Compatibilidad con R y Python
- Con IBM SPSS Statistics, se instalan la versión R 4.0.x y el paquete de integración IBM SPSS Statistics Essentials for R. Puede seleccionar el entorno de R en el menú Editar.... Opciones... Ubicación de los archivos... Ubicación R.
- Los entornos virtuales de R y Python con los que trabaja SPSS ahora están disponibles para ejecutarse desde el sistema operativo.
- La integración de Python 2 ha dejado de ser soportada oficialmente.
Activación de licencias
El Administrador de activación de licencias permite la activación de licencias individuales y concurrentes.
Extensiones instaladas
De forma predeterminada se instalan más de las extensiones más utilizadas. Las extensiones son procedimientos adicionales implementados en Python o R e integrados en SPSS en forma de diálogos y comandos de sintaxis. Puede identificar dichas extensiones mediante el icono "+" en el menú.
Opciones avanzadas para exportar resultados
- Compatibilidad con la exportación al formato de Word *.docx
- La exportación a un archivo de texto se divide en 3 opciones que permiten elegir la codificación deseada: texto sin formato, UTF8, UTF16
- La exportación a Excel admite la creación de nuevos libros y la creación de nuevas hojas de cálculo en un libro existente
- Vista previa antes de imprimir ahora muestra la versión PDF del documento
Ocultar observaciones filtradas
Los casos que no satisfacen el filtro Seleccionar se pueden ocultar en el Editor de datos de forma que, al copiar datos, las observaciones ocultas no se copiarán en el portapapeles.
Generador avanzado de gráficos
En el cuadro de diálogo Asistente para gráficos, la ficha Apariencia del gráfico se ha rediseñado para facilitar la selección de la plantilla deseada.
