Los datos son representaciones digitales de la realidad y no existe una forma única de lograr dicha representación. Por ejemplo, para representar a un individuo como parte o no de una clase de nuestro interés (población objetivo o lo que sea), podemos usar un código de enteros binarios (1 = pertenece, 0 = no corresponde) o un par de cadenas ( "Sí", "no") u otras formas que podamos imaginar. Este caso simple ilustra muy bien la afirmación anterior: la misma realidad binaria expresada a través de símbolos de diferentes propiedades métricas.
Al transformar, analizar y representar datos, el conjunto de algoritmos aplicables depende de manera crítica de las propiedades métricas de las variables involucradas. En nuestro ejemplo anterior, imagine que queremos "contar" el número de personas que pertenecen a nuestra clase objetivo. Además, imagine que analizamos 5 individuos (o casos). Según la representación de los enteros, tendríamos algo como (1,1,1,0,0). Según la representación de las cadenas que tendríamos ("sí", "sí", "sí", "no", "no"). Con el fin de contar, bajo la representación de enteros podemos aplicar el algoritmo "suma" 1 + 1 + 1 + 0 + 0 = 3. Bajo la representación de cadenas necesitamos contar, lo que es equivalente a transformar internamente el "sí" en 1 y luego sumar.
Los algoritmos estadísticos y de minería de datos son bastante más complejos que un recuento simple y, por lo general, cualquier análisis requiere que se apliquen diversos algoritmos de modo secuencial. Para que los resultados tengan sentido, debemos tener en cuenta cómo representamos los datos y qué algoritmos cabe o no aplicar a la realidad subyacente a pesar de que sean aplicables a su representación digital elegida.
Esto hace imprescindible gestionar los metadatos. Por metadatos entendemos la información que usamos para describir los datos: los nombres de las variables, sus etiquetas, etiquetas de valor, propiedades métricas, la forma en que representamos la información faltante y cualquier otro atributo que podamos definir, como la fuente de datos, la fecha en que los obtuvimos ... ...
IBM SPSS Statistics ofrece un conjunto completo de procedimientos a tal fin, lo que permite al usuario acceder y administrar estos metadatos como enseguida veremos.
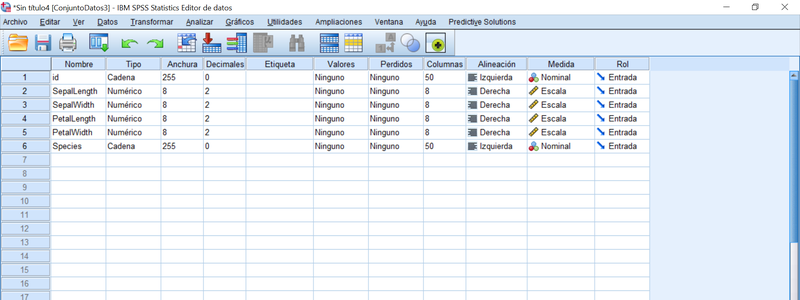
La imagen a continuación es la Vista de variables del Editor de datos. Bajo esta vista, el usuario obtiene acceso a los metadatos principales de las variables pudiendo modificarlos haciendo clic en las celdas apropiadas.
Archivo> Mostrar Información del Archivo de Datos. Muestra los metadatos del conjunto de datos activo o de archivos guardados en el editor de resultados.
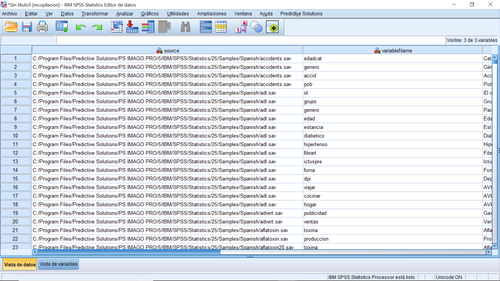
Archivo> Recopilar información de variable crea un conjunto de datos que contiene metadatos básicos de las variables contenidas en los archivos de una carpeta designada según la imagen a continuación:
Datos> Definir propiedades de variables lanza un proceso asistido que escanea los datos y permite al usuario definir diferentes metadatos de las variables, incluido el papel que desempeña cada variable para fines de modelado: entrada, objetivo, ambos, ninguno, partición, dividir ... dentro del marco de referencia del algoritmo de modelado particular que se aplicará.
Datos> Definir nivel de medición para desconocido algunos procedimientos están disponibles solo cuando se establecen todos los niveles de medición de variables. Este procedimiento permite establecer el nivel de medición para cualquier variable de la que se desconozca sin realizar un pase de datos que puede llevar mucho tiempo especialmente para grandes conjuntos de datos.
Datos> Copiar propiedades de datos: una manera fácil de reutilizar las propiedades de una variable existente en una nueva variable, evitando el trabajo innecesario y repetido. Defina una vez, aplique varias veces.
Datos> Nuevo atributo personalizado aquí, el usuario puede definir sus propios atributos para adjuntarlos a las variables seleccionadas (debe estar en la Vista de variables para habilitar esta opción).
Transformar> Recodificar en las mismas variables / en diferentes variables / Recodificación automática, estas son opciones de transformación que alteran la forma en que representamos nuestros datos y, por lo tanto, los metadatos.
Utilidades> Comentarios del archivo de datos permite agregar un comentario de texto que describe el conjunto de datos archivado.
Utilidades> Definir macro de variables es una forma de definir una macro SPSS cuyo valor es una lista de variables que satisfacen ciertos criterios tales como el nivel de medida, tipo, atributos variables y patrones en sus nombres. Mediante este enfoque, puede crear trabajos de sintaxis generalizada que no dependan de conocer los nombres exactos de las variables en un archivo de datos en particular. Por ejemplo, podría crear un trabajo que muestre estadísticas descriptivas apropiadas para las variables en un conjunto de datos en función de su escala de medida.
